Growing up, I had this huge obsession with robots; I used to watch almost every movie that had robots in it, whether that be Wall-E or Transformers and everything in between. I was obsessed. Last month, I was going down a massive youtube rabbit hole, one thing led to the next and I found myself learning about how humans learn to talk.
And one of the biggest takeaways from this entire 3-hour rabbit hole was that it’s completely trial and error. We humans just put words together until they make sense and the first thought that came to my mind was this:
If humans can speak/write through trial and error, how does a computer do all this?
This simple question was the beginning of many deep rabbit holes. I read so many research papers and with every research paper I read, the next one magically became longer.
Before I get into any specifics, researching how computers can interpret data and convert it into something they can understand was so cool. One thing led to the next and I lost track of time, but I spent hours of researching. The key takeaway was that I’ve never felt dumber. My understanding of how a computer would read text was completely wrong, I thought it was a 2 step process, similar to how a normal human would, but I was way off 😭. From a very high level, there are so many layers and levels to how computers can understand data and text structures: from summarizing papers to chatbots to everything in between, computers can do it all. The potential that computers hold to change the world of communicating is enthralling!
All of this comes down to one key subset of Artificial Intelligence: Natural Language Processing. However, this subset of AI is broken down further so let’s get right into it 😇
So what is Natural Language Processing 🤔
As mentioned previously, Natural Language Processing is a subset of Artificial Intelligence; its main function is to help computers understand words and sentences that are written in a language that a human understands. Natural Language Processing uses computational linguistics, which is essentially a model of human language. It also employs the use of machine learning and deep learning models. By coupling these models together, it allows for these complex computer systems to understand the human language, whether that be in the form of text or audio.
Natural Language Processing allows developers to do a variety of things with unstructured data; this includes automatic summarization, translation, named entity recognition, relationship extraction, sentiment analysis, speech recognition, and topic segmentation.
Those are some complex words but don’t worry, the one we’ll be focusing on is summarization 😁
Generally, Natural Language Processing is a difficult problem in AI/Computer Science. The reason for this is that the human language is very complex, but it’s also not very precise. This lack of precision in the human language makes it difficult for computer systems to understand the words, but also how they’re connected and how they work together. All of this boils down to the ambiguity of the human language. But let’s break down NLP a bit; Natural Language Processing is broken down into 2 portions: Natural Language Understanding & Natural Language Generations.
Natural Language Understanding
Natural Language Understanding is a subset of NLP; the overarching goal of NLU is to determine the meaning/understanding of a sentence. This is achieved through the use of syntactic and semantic analysis of speech/text. The syntax is the structure of a sentence, whereas the semantics of a sentence refers to the meaning. The goal of syntactic analysis is to tell us the logical meaning/understanding of a sentence or a certain part of these sentences. To do this, a semantic structure is assigned to a piece of text. It’s known as syntax analysis or parsing. But we’ll dive further into this later on in this article. On the other hand, semantic analysis allows computer systems to draw meaning from the text. This semantic analysis allows computers to interpret the meaning of different forms of text by analyzing the grammatical structure and recognizing relationships between certain words.
The 2 biggest applications of Natural Language Understanding are creating chatbots and voice bots. This is a way for these computer systems to interact with humans without supervision. To achieve this feat, NLU is employed to extract the meaning of human speech and convert it into a structured ontology. Structured ontology is a data model that consists of the semantics and pragmatics definitions. This boils down to 2 key concepts of NLU: Intent recognition and Entity recognition.
The goal of intent recognition is to identify the sentiment of the message/text and determine its overall objective of it. Entity recognition is a very specific type of Natural Language Understanding; it’s focused on extracting the entity of the message. Following this, the most important information is then highlighted/extracted. There are 2 types of entities that exist: named entities and numeric entities. The key difference between these 2 types of entities is that named entities are highly focused on words and categories, such as people and locations. On the other hand, numeric entities are focused on numbers, currencies and percentages.

Now that we understand Natural Language Understanding, let’s take a look at Natural Language Generation.
Natural Language Generation
Natural Language Generation is the second subset of Natural Language Processing. NLG is also known as the complementary process of NLU; they work together to achieve the overall goal of Natural Language Processing. NLG is highly focused on generating human language text responses by utilizing data inputs. The output text can also be converted into an audio format; this is done by using text-to-speech. In order for Natural Language Generation to work, there are 6 key steps.
1. Content Determination
In this stage, the boundaries of the content are determined. When it comes to data surrounding Natural Language Processing, there’s a lot of unnecessary information and this needs to be filtered out.
2. Data Interpretation
In this step, the data that was determined in the previous step is analyzed. ML techniques are employed in this step to identify patterns while processing the data. Along with this, the data is also put into context in this stage.
3. Document Planning
This step is focused on the structure of the data. In simple terms, the data is organized by creating a narrative structure and a documented plan.
4. Sentence Aggregation
Another term for this step is called micro-planning. In this step, it’s all about picking the specific expressions/words that are utilized in every sentence. They are aggregated, hence the name sentence aggregation.
5. Grammaticalization
We can imagine this step as an in-built Grammarly. In this step, the whole report is checked and analyzed to ensure that it’s grammatically correct.
6. Language Implementation
This is the final step of the NLG process; in this step, the document is put into the correct format according to what the user prefers.
Now that we understand the basics of NLU and NLG, let’s dive into how Natural Language Processing works
Pre-Processing Data in NLP
In Natural Language Processing, there’s a lot of text data that is inputted, but this data can’t be used right away, it needs to be preprocessed before. Once it’s preprocessed, this data can be understood and used by the machine learning algorithms. There are many steps in pre-processing so let’s get right into it.
Sentence Tokenization
This is the very first step in pre-processing the data. Sentence tokenization, also known as sentence segmentation is the process of taking text data and splitting it into its individual sentences. The fundamental idea here is very easy to understand as the end of each sentence is marked with a period. This step is done on the assumption that each sentence is uniquely different and carries a separate idea. By doing this, it makes it easier for our computer system to understand the overall meaning of the text data; it’s easier to process individual sentences instead of large paragraphs. However, there’s a problem when it comes to abbreviations that contain periods. To get around this, there’s a table of abbreviations that exist that prevent from this preprocessing being inaccurate.
Word Tokenization
This process is very similar to the previous step. Word tokenization, also known as word segmentation, is the process of dividing taking sentences and breaking them down into individual words. Similar to sentence tokenization, the fundamental idea is extremely easy to understand; a space is typically the character that acts as a word divider. Similar to sentence tokenization, there are some cases where the space won’t always act as a word divider. There are a few English compound nouns that are exceptions to this and to get around this, some NLP libraries are used to avoid confusion. Let’s take an example, if we had this simple abbreviation: Natural Language Processing, it would be tokenized into this:
[‘Natural’, ‘Language’, ‘Processing’]

Part-of-Speech Tagging
The next step in the NLP pipeline is to look at the individual tokens and guess the part of speech of each token. Part of speech is very similar to what we’re taught when we’re first learning how to speak. In this case, the computer system would be tagging each token with a noun, verb, adjective, etc. By identifying the role of each token/word, the computer system will be able to identify the meaning of the sentence and figure out what the sentence is trying to say. This isn’t as simple as looking at a word and the computer can identify the Part of Speech of each token, there are some important computer processes that must take place first. To do this, each token (word) and the surrounding words for context, are fed through a part-of-speech classification model. This model has been trained with millions of English words and sentences. In order to train this model, tokens are fed into the model with their part-of-speech tagged beforehand. By doing this, the model is able to learn and identify the part-of-speech of the words. Let’s look at an example of this:

Now that we have the part of speech identified of each word, the computer system can now take this information and understand what the sentence is trying to say. Another way to look at it is that the action of tagging words is a disambiguation task, whereas words are ambiguous and the overall goal of POS tagging is to get rid of these ambiguities.
Lemmatization & Stemming
The next step in Natural Language Processing is text lemmatization. This sounds very complex and confusing at first but stay with me, let’s break this down. In the English language, words have the tendency to appear in different forms, whether that be a different tense or plural. Let’s look at an example:
I only have one try at this
I only have two tries at this
In both of these sentences, the verb word try is used, but they have different inflections; in other words, they have a different forms. Computer systems aren’t like humans, they won’t be able to simply look at a word and know where it’s derived from. To help computers understand this concept, computers need to know the base of the word. In Natural Language Processing, this is known as Lemmatization; which is essentially finding the basic form of each word. Another word for this is lemma hence the name lemmatization. This applies to all forms and types of words. To achieve the end result of this process, there’s a table of all the lemma forms of words: it’s filtered by the part of speech.

Stop Word Removal
After the root of the word has been identified, we need to remove something called stop words. Stop words are commonly used words in any language, for example, in the English language we have words such as a, the, is, are, etc. They don’t carry much value and this is why this step is followed through with. These filler words appear a lot more than other words and they must be filtered out/removed as they add a lot of noise when using the machine learning algorithm; this must be done before any further analysis is done in the NLP pipeline. So this is what a sample sentence would look like:

There isn’t a universal list of stop words, but for every unique application, there’s a list of stop words made for the computer system to use. In order to verify and identify stop words, there’s a hardcoded list of stop words for the computer system to utilize.
Dependency Parsing
After removing stop words, the NLP pipeline can finally move onto the next step, where the computer system learns how all the words in the sentence relate to each other. This is done through a process known as dependency parsing. In this case, we don’t look at the rules of sentence structure, rather we look at the syntactic structure and how they are grammatically related to each other. The way this is done is by building a tree that essentially labels each word with a single parent word. The relations between the words are visualized with labels that connect among different words; showing the grammatical relations between each word. These labels that are used can be found at Universal Dependency Relations. The root of the sentence will be the main verb of the entire sentence.
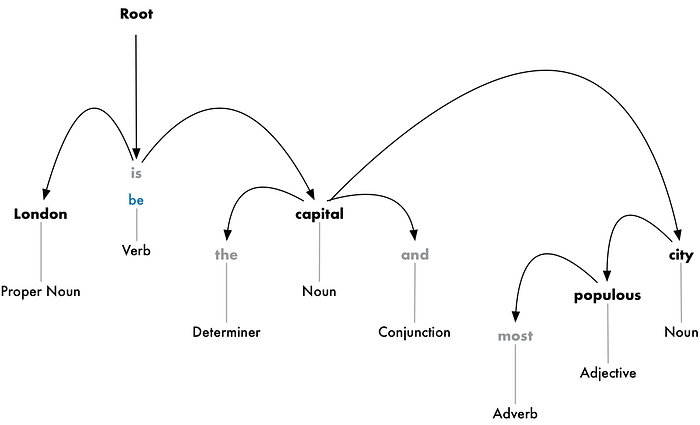
This diagram above is known as a parse tree and it is a visual representation of the relationships between all words. In this particular example, we can see that London has a relation with be and capital. From this knowledge alone, we can interpret that London is a capital. This intuitive way of interpreting a parse tree can be used for any of the other words in this sentence. However, a computer wouldn’t just know how to parse each word nor will they know how to generate a parse tree. In order to do this to maximum accuracy, the computer needs to be trained to identify each word and generate these relationships. Similar to how the part-of-speech portion of the NLP pipeline employed Machine Learning algorithms, this part also does. Dependency parsing works by inputting words and sentences through a Machine Learning algorithm/model to generate an output result.
Identifying Noun Phrases
Up until this point, we’ve dealt with words as if they are mutually exclusive. However, in most sentences, words can be grouped together because the entire goal of a sentence is to communicate a single message to the reader. As a result, the words are going to be related to each other in one way or the other, as such, it makes a lot of sense to group these words together, depending on the idea they represent. In the previous step, we formed a dependency parse tree, the data/knowledge from this tree is vital in grouping these words together. If we use the example from earlier, we have:

This can be changed up and grouped to generate this:

This step isn’t mandatory, but it helps in simplifying the sentence. It also helps a lot in getting rid of unnecessary items such as adjectives that don’t add value or meaning to the overall sentence. This allows the pipeline to focus on extracting key ideas from the sentence.
Named Entity Recognition (NER)
Everything we’ve done up to this point is very basic grammar stuff, now we’re going to shift into extracting key ideas to help summarize the text. In the 7 steps leading up to this one, we’ve identified some key nouns in our sentence:

In this case, the nouns that we’ve extracted are representative of things that exist in the real world. For example, London, England and United Kingdom are all real geographic places in the world. This information would be extremely helpful for our computer system! This information would help the computer systems extract and document real-world places with NLP.
This can be achieved through Named Entity Recognition or NER. The overarching goal of NER is to extract these nouns and label them with the real-world image that they represent. For example, London would be considered a geographic entity because that is its real-world representation. Now if we were to run this through the Named Entity Recognition tagging model, we would get something that looks like this:

The Named Entity Recognition system doesn’t simply look at a document full of geographic/physical locations and label these nouns. The system looks at the context of the noun, which the NLP pipeline extracted earlier and uses a statistical model to assign the correct entity to each noun. Here are a few examples of what the NER system can label:
- Names of people
- Company names
- Geographic locations
- Names of products
- Dates + times
- Money
- Event names
This entire process is made extremely easy for the NER system as it isn’t difficult to extract structured data out of pieces of text.
Coreference Resolution
So far, we’ve got a valuable representation of the sentence in terms of the POS of each word, relationships between words and most recently, their entities. When looking at language processing, a key component of it is to know who is being discussed/talked about in the piece of text.
Pronouns are a big part of language processing, specifically, pronouns such as he/she/they/it. They are placeholders and shortcuts that are used instead of writing out names of places and people in each sentence. Identifying the noun the pronoun is associated with is easy for the human eye as we can extract the meaning based on context. However, as mentioned previously, the computer systems that employ NLP are only able to inspect/examine one sentence at a time.
For example: (this is a sentence that is mentioned later on in the Wikipedia page that I used)
“It was founded by the Romans, who named it Londinium.”
If we were to run this sentence through the NLP pipeline, the computer system would only know that “it” is something that was founded by the Romans. However, if a human was to read this sentence, we would be able to identify that from context, “it” is actually referring to “London”. This is the exact purpose of coreference resolution; map out the sentence by tracking pronouns across all the sentences.

This is the final step in the NLP pipeline, now that we have the coreference resolution information, combining that with the parse tree and NER information, we can do a lot of things with NLP, the potential is limitless! Putting everything together, this is what our final pipeline looks like:

If you’ve made it this far, I hope you enjoyed the article and took some knowledge away from it! That’s a wrap from me :)
If you enjoyed this article, feel free to connect on LinkedIn 😁
